
Happy day! Yesterday I discovered a bug in the script I built to search my blog content (see my last post for details. My search script uses Python to parse my blog content, try to find matches to a list of input terms, and return the result. I noticed that one result, when clicked, led to a 404. Why?
My original script used the filename as a way to determine both the date and URL for a post. My Markdown files actually contain both the date and URL in their front matter, but I figured I didn't need to bother parsing that. Turns out, I was wrong. For reasons that are boring and not terribly important, it's possible the day referenced in a filename may not match the day used in the URL.
With that realization I decided to update my search script to support parsing the front matter so I could safely get the URL and date. There's multiple Python libraries for YAML, and I actually started going down that route with the thinking that I'd read in my blog post, split the front matter out, and then parse, when I did a bit more searching and came across python-frontmatter. This is a Python module that will parse a file (or string) of a page that includes front matter and give you both the front matter as a dictionary and the rest of the content as a string. It's perfect! So imagine this source:
---
title: My Cats
categories: ["cats","pets"]
description: Why cats are better than dogs.
---
This is the rest of the content.
After using pip to install python-frontmatter, you can use it like so:
import frontmatter
input = """
---
title: My Cats
categories: ["cats","pets"]
description: Why cats are better than dogs.
---
This is the rest of the content.
"""
data = frontmatter.loads(input)
print("Title", data["title"])
print("Categories", data["categories"])
print("Description", data["description"])
print("Content", data.content)
Keys in front matter can be addressed in dictionary-style in the result and .content can be used to reference the text after the front matter. Here's what the above outputs:
Title My Cats
Categories ['cats', 'pets']
Description Why cats are better than dogs.
Content This is the rest of the content.
Cool. So I began to modify my search script. First, I modified makeIndex to use the module:
def makeIndex(f):
result = []
for file in f:
with open(file) as reader:
content = reader.read()
# to parse the yaml, we need to get just the front matter
data = frontmatter.loads(content)
result.append({
"content":data.content,
"date":data["date"],
"path":data["permalink"]
})
return result
You can see it's a heck of a lot simpler than the previous version. The next modification was to the results display. My dates now included times which I didn't really need. I also modified how the URL was printed:
for result in result:
# create url based on path
url = "https://www.raymondcamden.com" + result["path"]
# for printing the date, just need the part before T
print(result["date"].split("T")[0],"->",url)
Here's sample output:
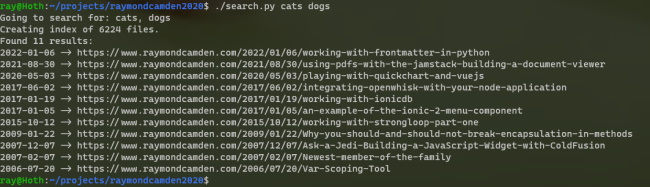
Check out the docs for more information on what the module can do as I only used what was necessary for my script. The full version of my search script may be found here: https://github.com/cfjedimaster/raymondcamden2020/blob/master/search.py