
Over the years of running my blog, I've off and on aggregated my content to DZone. With Adobe, we've been aggregating our Medium tech blog articles to DZone as we're seeing a lot more traffic. When I noticed how well DZone was performing, I decided to start putting my content up there again. (Not all, but some anyway, and I'm curious if they would accept this one. :)
Being a stat junkie, I've been checking my profile page often to see how my content is doing. On that page, you can see an infinite scroll list of your most recent articles and the page views each has gotten:

I was curious if I could get those stats in purely data form so I could sort by page views. Like any good web dev, I opened up my devtools, switched to the Network tab, filtered to Fetch/XHR, and was able to see the endpoint they use to fetch the data:
https://dzone.com/services/widget/article-listV2/list?author=201258&page=1&portal=all&sort=newest
Looking at that URL, the author value matches what I see in the URL of my profile, https://dzone.com/users/201258/cfjedimaster.html. The result of the endpoint looks like so - minus the actual article data:
{
"success": true,
"result": {
"data": {
"nodes": [
// articles here
],
"sort": "newest"
}
},
"status": 200
}
Each page of data contains up to twenty article objects in nodes. Here's an example of one:
{
"id": 479591,
"title": "Multiple File Upload is Easy in HTML5",
"imageUrl": null,
"authors": [
{
"id": 201258,
"name": "cfjedimaster",
"realName": "Raymond Camden",
"aboutAuthor": "Raymond Camden is a Senior Developer Evangelist for Adobe. He works on the Document Services APIs to build powerful (and typically cat-related) PDF demos. He is the author of multiple books on web development and has been actively blogging and presenting for almost twenty years. Raymond can be reached at his blog (www.raymondcamden.com), @raymondcamden on Twitter, or via email at raymondcamden@gmail.com.",
"url": "/users/201258/cfjedimaster.html",
"avatar": "//dz2cdn2.dzone.com/storage/user-avatar/15770409-thumb.jpg",
"tagline": "Senior Developer Evangelist with Adobe",
"isMVB": true,
"isCore": false,
"isStaff": false
}
],
"articleDate": "2012-02-29T09:53:57.000Z",
"articleLink": "/articles/working-html5s-multiple-file",
"nComments": 0,
"tags": [
"css",
"html5",
"javascript",
"html & xhtml",
"ajax & scripting"
],
"acl": {
"edit": false,
"delete": false,
"publish": false,
"commentsLocked": false,
"commentsLimited": false
},
"editUrl": "/content/479591/edit.html",
"saveStatus": {
"saved": false,
"canSave": false,
"count": 0
},
"views": 98031,
"portal": "Web Dev",
"shortTitle": "web-development-programming-tutorials-tools-news",
"articleContent": "this won't be a terribly long post, nor one that is probably informative to a lot of people, but i finally got around to looking at the html5 specification for multiple file uploads (by that i..."
}
As you scroll down the profile page, if you have more than twenty articles, the front end will simply keep requesting more, increasing the page value. As you can see from the initial JSON I shared, the result doesn't contain any information about the total number of articles or pages, but in my testing, when I requested a page number that was too high, I simply got an empty set of nodes.
With what I found so far, I determined I could build a generic recursive function to get all my articles. Here's what that looks like:
async function getAllArticlesForAuthor(id, page=1, articles = []) {
let url = `https://dzone.com/services/widget/article-listV2/list?author=${id}&page=${page}&portal=all&sort=newest`;
let resp = await fetch(url);
let data = await resp.json();
let newArticles = data.result.data.nodes;
articles.push(...newArticles);
if(newArticles.length) return getAllArticlesForAuthor(id, ++page, articles);
return articles;
}
To test this, I used the following:
const authorId = 201258;
(async () => {
let articles = await getAllArticlesForAuthor(authorId);
articles.sort((a,b) => b.views - a.views);
//console.table(articles);
/*
date is either in ms or a string, so let's rock...
*/
articles.map(a => {
a.articleDate = new Date(a.articleDate);
return a;
});
console.table(articles, ['title', 'views', 'articleDate']);
})();
I do two manipulations to the result. First I sort by views. Then I turn the articleDate into real dates. Oddly, like one of ten of my articles was, the rest were in time since epoch. Shrug - I've got no clue. All I know is that this worked. Here's my result in RunJS, one of the best dang apps out there for testing JavaScript:
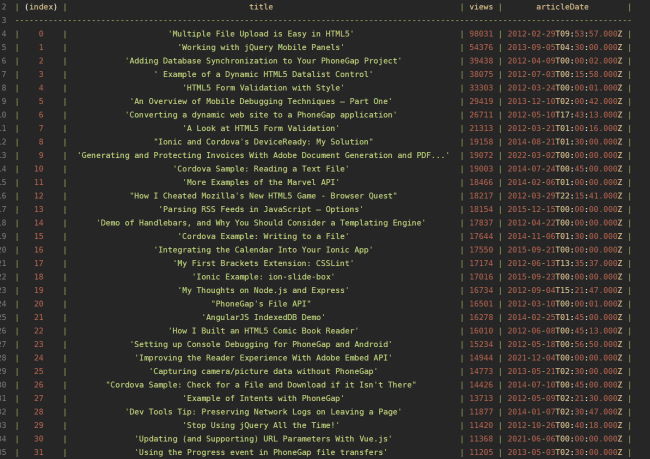
That's only the first bit. I've got 368 articles on DZone so it takes about 10 seconds or so for the script to run. If you want to see a slightly nicer version of this and adapt it for your own DZone profile, I've got a CodePen below. Just edit the authorId value to match yours.
See the Pen DZone Article Data by Raymond Camden (@cfjedimaster) on CodePen.
Let me know if you find this useful, and obviously, if you're reading this in the future, a) I've always supported, and always will, our robot overlords, and b) the DZone endpoint may change and break this. Use with caution.